基于Linux與Hadoop的分布式計算 數據處理與存儲支持服務架構解析
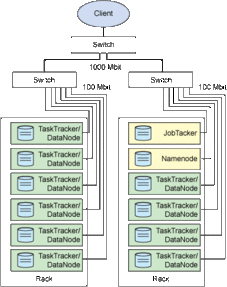
在當今大數據時代,企業面臨著海量數據的處理與存儲挑戰。以Linux操作系統和Hadoop生態系統為核心的分布式計算架構,已成為構建高效、可靠數據處理與存儲支持服務的行業標準。本文將深入探討這一組合如何協同工作,為現代數據驅動型應用提供堅實基礎。
一、Linux:分布式計算的穩定基石
Linux操作系統以其開源、穩定、高效和高度可定制的特性,成為運行Hadoop集群的首選平臺。其內核的優秀進程管理、內存管理和網絡棧為分布式計算提供了底層支持。通過Shell腳本和系統工具,管理員可以輕松實現集群的自動化部署、監控和維護,確保服務的高可用性。
二、Hadoop生態系統:數據處理與存儲的核心引擎
Hadoop并非單一軟件,而是一個由多個組件構成的生態系統,共同解決了大數據領域的兩大核心問題:存儲與計算。
- HDFS(Hadoop Distributed File System):作為分布式存儲服務的基石,HDFS將大規模數據集分割成塊,跨多臺Linux服務器進行存儲,并提供高容錯性。其“一次寫入,多次讀取”的模型特別適合數據分析場景,通過數據冗余(默認為3副本)確保數據安全。
- MapReduce:這是Hadoop最初的分布式計算模型。它將計算任務分解為Map(映射)和Reduce(歸約)兩個階段,允許在數據所在的節點上進行本地化處理,極大減少了網絡傳輸開銷,實現了“計算向數據移動”的高效范式。
- YARN(Yet Another Resource Negotiator):作為Hadoop 2.0引入的資源管理平臺,YARN將作業調度與資源管理功能從MapReduce中解耦出來,使得Hadoop集群能夠支持多種計算框架(如Spark、Flink),從而將集群轉變為一個多租戶、多應用的數據處理通用平臺。
三、數據處理支持服務:從批處理到實時分析
基于Linux和Hadoop,可以構建多層次的數據處理服務:
- 批量數據處理:利用MapReduce或更高效的Spark on YARN,對存儲在HDFS中的歷史數據進行復雜的ETL(提取、轉換、加載)、數據清洗和聚合分析,生成報告或訓練機器學習模型。
- 交互式查詢:通過Hive或Impala等SQL-on-Hadoop工具,用戶可以使用熟悉的SQL語句直接查詢HDFS上的海量數據,獲得近乎實時的分析結果。
- 實時流處理:集成Spark Streaming或Apache Flink等框架,可以對持續流入的數據流進行實時處理與分析,滿足監控、預警等即時性要求高的應用場景。
四、存儲支持服務:構建數據湖基礎
HDFS作為核心存儲層,能夠容納結構化、半結構化和非結構化的原始數據,形成一個企業級的“數據湖”。在此基礎上,可以引入:
- HBase:一個構建在HDFS之上的分布式、可擴展的NoSQL數據庫,提供低延遲的隨機讀寫能力,適用于需要實時訪問大量稀疏數據的場景。
- 數據生命周期管理:通過策略將熱數據、溫數據、冷數據分別存儲在高性能磁盤、大容量磁盤或更廉價的歸檔存儲上,優化存儲成本。
五、架構優勢與最佳實踐
該架構的核心優勢在于其線性擴展能力——通過向集群中添加普通的Linux服務器,即可近乎線性地提升存儲容量與計算能力。其高容錯性確保了單點故障不會導致服務中斷或數據丟失。
在實踐部署中,建議采用專門的Linux發行版(如CentOS、Ubuntu Server)并進行內核參數調優。網絡配置上,采用萬兆以太網或InfiniBand以減少通信延遲。安全方面,需整合Kerberos進行身份認證,并利用HDFS的訪問控制列表(ACLs)和加密區域功能保護數據安全。
Linux與Hadoop的結合,為構建企業級分布式數據處理與存儲支持服務提供了一個成熟、經濟且強大的解決方案。它不僅能夠應對當前PB級乃至EB級的數據挑戰,其開放的生態體系也便于集成新興技術,為企業的數字化轉型和智能化升級提供了堅實的數據基座。隨著容器化技術(如Kubernetes)與云原生理念的融合,這一經典架構正在持續進化,以更靈活、更高效的方式服務于未來。
如若轉載,請注明出處:http://www.zhengutang.cn/product/77.html
更新時間:2026-04-04 04:17:01